Normalization
Problems without Normalization in DBMS
If a table is not properly normalized and has data redundancy(repetition) then it will not only eat up extra memory space but will also make it difficult for you to handle and update the data in the database, without losing data.
Insertion, Updation, and Deletion Anomalies are very frequent if the database is not normalized.
To understand these anomalies let us take an example of a Student table.
| rollno | name | branch | hod | office_tel |
|---|---|---|---|---|
| 401 | Akon | CSE | Mr. X | 53337 |
| 402 | Bkon | CSE | Mr. X | 53337 |
| 403 | Ckon | CSE | Mr. X | 53337 |
| 404 | Dkon | CSE | Mr. X | 53337 |
In the table above, we have data for four Computer Sci. students.
As we can see, data for the fields branch, hod(Head of Department), and office_tel are repeated for the students who are in the same branch in the college, this is Data Redundancy.
1. Insertion Anomaly in DBMS
Suppose for a new admission, until and unless a student opts for a branch, data of the student cannot be inserted, or else we will have to set the branch information as NULL.
Also, if we have to insert data for 100 students of the same branch, then the branch information will be repeated for all those 100 students.
These scenarios are nothing but Insertion anomalies.
If you have to repeat the same data in every row of data, it's better to keep the data separately and reference that data in each row.
So in the above table, we can keep the branch information separately, and just use the branch_id in the student table, where branch_id can be used to get the branch information.
2. Updation Anomaly in DBMS
What if Mr. X leaves the college? or Mr. X is no longer the HOD of the computer science department? In that case, all the student records will have to be updated, and if by mistake we miss any record, it will lead to data inconsistency.
This is an Updation anomaly because you need to update all the records in your table just because one piece of information got changed.
3. Deletion Anomaly in DBMS
In our Student table, two different pieces of information are kept together, the Student information and the Branch information.
So if only a single student is enrolled in a branch, and that student leaves the college, or for some reason, the entry for the student is deleted, we will lose the branch information too.
So never in DBMS, we should keep two different entities together, which in the above example is Student and branch
Primary Key and Non-key attributes
Before we move on to learn different Normal Forms in DBMS, let's first understand what is a primary key and what are non-key attributes.
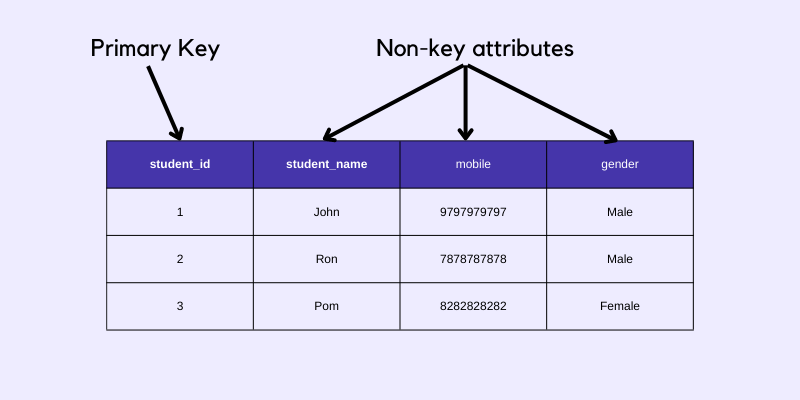
As you can see in the table above, the student_id column is a primary key because using the student_id value we can uniquely identify each row of data, hence the remaining columns then become the non-key attributes.
Database Normal Forms
Here is a list of Normal Forms in SQL:
- 1NF (First Normal Form)
- 2NF (Second Normal Form)
- 3NF (Third Normal Form)
- BCNF (Boyce-Codd Normal Form)
- 4NF (Fourth Normal Form)
- 5NF (Fifth Normal Form)
First Normal Form
First Normal Form is defined in the definition of relations (tables) itself. This rule defines that all the attributes in a relation must have atomic domains. The values in an atomic domain are indivisible units.
For a table to be in the First Normal Form, it should follow the following 4 rules:
It should only have single(atomic) valued attributes/columns.
Values stored in a column should be of the same domain.
All the columns in a table should have unique names.
And the order in which data is stored should not matter.
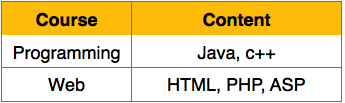
We re-arrange the relation (table) as below, to convert it to First Normal Form.
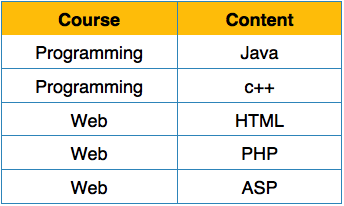
Each attribute must contain only a single value from its pre-defined domain.
Second Normal Form
Before we learn about the second normal form, we need to understand the following −
Prime attribute − An attribute, which is a part of the candidate-key, is known as a prime attribute.
Non-prime attribute − An attribute, which is not a part of the prime-key, is said to be a non-prime attribute.
For a table to be in the Second Normal Form,
It should be in the First Normal form.
And, it should not have Partial Dependency.
What is Partial Dependency?
When a table has a primary key that is made up of two or more columns, then all the columns(not included in the primary key) in that table should depend on the entire primary key and not on a part of it. If any column(which is not in the primary key) depends on a part of the primary key then we say we have Partial dependency in the table.
If we follow second normal form, then every non-prime attribute should be fully functionally dependent on prime key attribute. That is, if X → A holds, then there should not be any proper subset Y of X, for which Y → A also holds true.
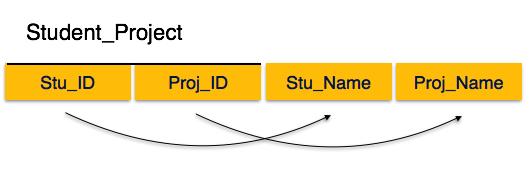
We see here in Student_Project relation that the prime key attributes are Stu_ID and Proj_ID. According to the rule, non-key attributes, i.e. Stu_Name and Proj_Name must be dependent upon both and not on any of the prime key attribute individually. But we find that Stu_Name can be identified by Stu_ID and Proj_Name can be identified by Proj_ID independently. This is called partial dependency, which is not allowed in Second Normal Form.
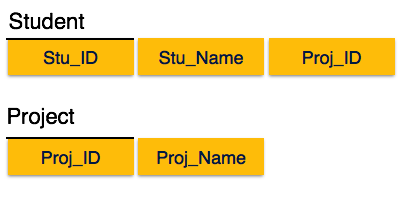
We broke the relation in two as depicted in the above picture. So there exists no partial dependency.
Third Normal Form
For a relation to be in Third Normal Form, it must be in Second Normal form and the following must satisfy −
A table is said to be in the Third Normal Form when,
It satisfies the First Normal Form and the Second Normal form.
And, it doesn't have Transitive Dependency.
What is Transitive Dependency?
In a table we have some column that acts as the primary key and other columns depends on this column. But what if a column that is not the primary key depends on another column that is also not a primary key or part of it? Then we have Transitive dependency in our table.
- No non-prime attribute is transitively dependent on prime key attribute.
- For any non-trivial functional dependency, X → A, then either −
- X is a superkey or,
- A is prime attribute.

We find that in the above Student_detail relation, Stu_ID is the key and only prime key attribute. We find that City can be identified by Stu_ID as well as Zip itself. Neither Zip is a superkey nor is City a prime attribute. Additionally, Stu_ID → Zip → City, so there exists transitive dependency.
To bring this relation into third normal form, we break the relation into two relations as follows −
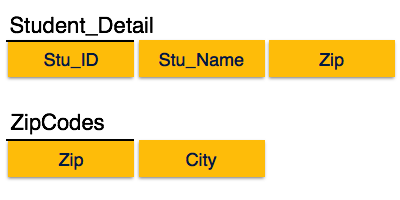
Boyce-Codd Normal Form
Boyce-Codd Normal Form (BCNF) is an extension of Third Normal Form on strict terms. BCNF states that −
- For any non-trivial functional dependency, X → A, X must be a super-key.
Boyce and Codd Normal Form is a higher version of the Third Normal Form.
This form deals with a certain type of anomaly that is not handled by 3NF.
A 3NF table that does not have multiple overlapping candidate keys is said to be in BCNF.
For a table to be in BCNF, the following conditions must be satisfied:
R must be in the 3rd Normal Form
and, for each functional dependency ( X → Y ), X should be a Super Key.
In the above image, Stu_ID is the super-key in the relation Student_Detail and Zip is the super-key in the relation ZipCodes. So,
Stu_ID → Stu_Name, Zip
and
Zip → City
Which confirms that both the relations are in BCNF.
Fourth Normal Form (4NF)
A table is said to be in the Fourth Normal Form when,
It is in the Boyce-Codd Normal Form.
And, it doesn't have Multi-Valued Dependency.
What is Multi-valued Dependency?
A table is said to have multi-valued dependency, if the following conditions are true,
- For a dependency A → B, if for a single value of A, multiple value of B exists, then the table may have multi-valued dependency.
- Also, a table should have at-least 3 columns for it to have a multi-valued dependency.
- And, for a relation
R(A,B,C), if there is a multi-valued dependency between, A and B, then B and C should be independent of each other.
If all these conditions are true for any relation(table), it is said to have multi-valued dependency.
Time for an Example
Below we have a college enrolment table with columns s_id, course and hobby.
| s_id | course | hobby |
|---|---|---|
| 1 | Science | Cricket |
| 1 | Maths | Hockey |
| 2 | C# | Cricket |
| 2 | Php | Hockey |
As you can see in the table above, student with s_id 1 has opted for two courses, Science and Maths, and has two hobbies, Cricket and Hockey.
You must be thinking what problem this can lead to, right?
Well the two records for student with s_id 1, will give rise to two more records, as shown below, because for one student, two hobbies exists, hence along with both the courses, these hobbies should be specified.
| s_id | course | hobby |
|---|---|---|
| 1 | Science | Cricket |
| 1 | Maths | Hockey |
| 1 | Science | Hockey |
| 1 | Maths | Cricket |
And, in the table above, there is no relationship between the columns course and hobby. They are independent of each other.
So there is multi-value dependency, which leads to un-necessary repetition of data and other anomalies as well.
How to satisfy 4th Normal Form?
To make the above relation satify the 4th normal form, we can decompose the table into 2 tables.
CourseOpted Table
| s_id | course |
|---|---|
| 1 | Science |
| 1 | Maths |
| 2 | C# |
| 2 | Php |
And, Hobbies Table,
| s_id | hobby |
|---|---|
| 1 | Cricket |
| 1 | Hockey |
| 2 | Cricket |
| 2 | Hockey |
Now this relation satisfies the fourth normal form.
A table can also have functional dependency along with multi-valued dependency. In that case, the functionally dependent columns are moved in a separate table and the multi-valued dependent columns are moved to separate tables.
If you design your database carefully, you can easily avoid these issues.
Fifth Normal Form (5NF)
The fifth normal form is also called the PJNF - Project-Join Normal Form
It is the most advanced level of Database Normalization.
Using Fifth Normal Form you can fix Join dependency and reduce data redundancy.
It also helps in fixing Update anomalies in DBMS design.
The stages of normalization are:
| Stage | Redundancy Anomalies Addressed |
|---|---|
| Unnormalized Form (UNF) | The state before any normalization. Redundant and complex values are present. |
| First Normal Form (1NF) | Repeating and complex values split up, making all instances atomic. |
| Second Normal Form (2NF) | Partial dependencies decompose to new tables. All rows functionally depend on the primary key. |
| Third Normal Form (3NF) | Transitive dependencies decompose to new tables. Non-key attributes depend on the primary key. |
| Boyce-Codd Normal Form (BCNF) | Transitive and partial functional dependencies for all candidate keys decompose to new tables. |
What is a KEY?
A database key is an attribute or a group of features that uniquely describes an entity in a table. The types of keys used in normalization are:
- Super Key. A set of features that uniquely define each record in a table.
- Candidate Key. Keys selected from the set of super keys where the number of fields is minimal.
- Primary Key. The most appropriate choice from the set of candidate keys serves as the table's primary key.
- Foreign Key. The primary key of another table.
- Composite Key. Two or more attributes together form a unique key but are not keys individually.
As tables decompose into multiple simpler tables, keys define a point of reference for a database entity.
For example, in the following database structure:

Some examples of super keys in the table are:
- employeeID
- (employeeID, name)
All super keys can serve as a unique identifier for each row. On the other hand, the employee's name or age are not unique identifiers because two people could have the same name or age.
The candidate keys come from the set of super keys where the number of fields is minimal. The choice comes down to two options:
- employeeID
Both options contain a minimal number of fields, making them optimal candidate keys. The most logical choice for the primary key is the employeeID because an employee's email can change. The primary key in the table is easy to reference as a foreign key in another table.
Functional Database Dependencies
A functional database dependency represents a relationship between two attributes in a database table. Some types of functional dependencies are:
- Trivial Functional Dependency. A dependency between an attribute and a group of features where the original element is in the group.
- Non-Trivial Functional Dependency. A dependency between an attribute and a group where the feature is not in the group.
- Transitive Dependency. A functional dependency between three attributes where the second depends on the first and the third depends on the second. Due to transitivity, the third attribute is dependent on the first.
- Multivalued Dependency. A dependency where multiple values depend on one attribute.
Functional dependencies are an essential step in database normalization. In the long run, the dependencies help determine the overall quality of a database.
Database Normalization Example - How to Normalize a Database?
The general steps in database normalization work for every database. The specific steps of dividing the table as well as whether to go past 3NF depend on the use case.
Example Unnormalized Database
An unnormalized table has multiple values within a single field, as well as redundant information in the worst case.
For example:
| managerID | managerName | area | employeeID | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | East | 1 2 | David D. Eugene E. | 4 3 | Finance IT |
| 2 | Betty B. | West | 3 4 5 | George G. Henry H. Ingrid I. | 2 1 4 | Security Administration Finance |
| 3 | Carl C. | North | 6 7 | James J. Katy K. | 1 4 | Administration Finance |
Inserting, updating, and removing data is a complex task. Performing any alterations to the existing table has a high risk of losing information.
Step 1: First Normal Form 1NF
To rework the database table into the 1NF, values within a single field must be atomic. All complex entities in the table divide into new rows or columns.
The information in the columns managerID, managerName, and area repeat for each employee to ensure no loss of information.
| managerID | managerName | area | employeeID | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | East | 1 | David D. | 4 | Finance |
| 1 | Adam A. | East | 2 | Eugene E. | 3 | IT |
| 2 | Betty B. | West | 3 | George G. | 2 | Security |
| 2 | Betty B. | West | 4 | Henry H. | 1 | Administration |
| 2 | Betty B. | West | 5 | Ingrid I. | 4 | Finance |
| 3 | Carl C. | North | 6 | James J. | 1 | Administration |
| 3 | Carl C. | North | 7 | Katy K. | 4 | Finance |
The reworked table satisfies the first normal form.
Step 2: Second Normal Form 2NF
The second normal form in database normalization states that each row in the database table must depend on the primary key.
The table splits into two tables to satisfy the normal form:
- Manager (managerID, managerName, area)
| managerID | managerName | area |
|---|---|---|
| 1 | Adam A. | East |
| 2 | Betty B. | West |
| 3 | Carl C. | North |
- Employee (employeeID, employeeName, managerID, sectorID, sectorName)
| employeeID | employeeName | managerID | sectorID | sectorName |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finance |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | George G. | 2 | 2 | Security |
| 4 | Henry H. | 2 | 1 | Administration |
| 5 | Ingrid I. | 2 | 4 | Finance |
| 6 | James J. | 3 | 1 | Administration |
| 7 | Katy K. | 3 | 4 | Finance |
The resulting database in the second normal form is currently two tables with no partial dependencies.
Step 3: Third Normal Form 3NF
The third normal form decomposes any transitive functional dependencies. Currently, the table Employee has a transitive dependency which decomposes into two new tables:
- Employee (employeeID, employeeName, managerID, sectorID)
| employeeID | employeeName | managerID | sectorID |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Sector (sectorID, sectorName)
| sectorID | sectorName |
|---|---|
| 1 | Administration |
| 2 | Security |
| 3 | IT |
| 4 | Finance |
The database is currently in third normal form with three relations in total. The final structure is:
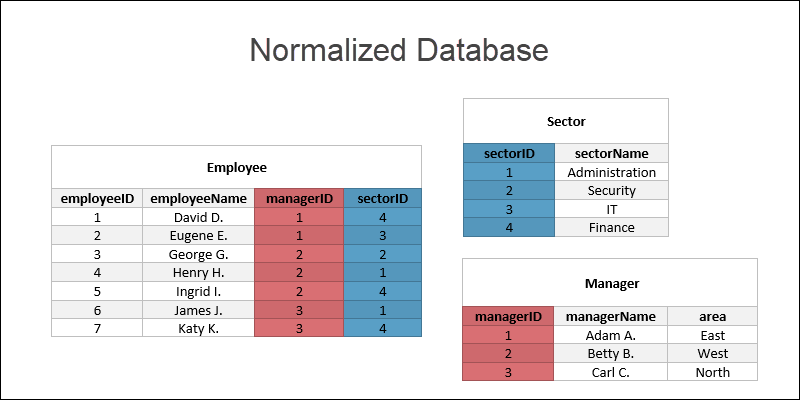


No comments:
Post a Comment